MCP my HTTPS!
I get it. Every innovation requires a rewrite by a newer (and typically younger) generation.
Containers, Blockchain, Crypto, WASM - they all could have been built on the existing tech (and, well, TLDs).
Yet hipsters gonna hip!
But every now and then something truly bizarre happens. To me, that’s MCP.
MC who?
Model Context Protocol (MCP) is a “standard” (gone are the days of standards taking more than 5 prompts minutes to be developed). Let me quote their website as I am already getting too snarky:
MCP is an open protocol that standardizes how applications provide context to LLMs. Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools.
The best part of it is that it draws a parallel to USB-C. Let me just refer to another quote, from Wikipedia’s article on USB-C:
USB-C, or USB Type-C, is a 24-pin, reversible connector (not a protocol) that supersedes previous USB connectors and can carry audio, video, and other data, to connect to monitors, external drives, hubs/docking stations, mobile phones, and many more peripheral devices.
So, lets get it staight. MCP is an open protocol, think of it like a USB-C port, which is not a protocol. Get it now? Good, let’s continue!
Why it exists? Well, the LLMs were moving so fast and were getting so good at doing human tasks and understanding existing tools like programming languages and APIs that humans have decided to create a whole new protocol for LLMs… to talk to APIs and do human tasks.

Okay, okay, don’t listen to the Ol’ Grumpy Sergei, let’s just refer to the holy specification, paragraph by paragraph:
MCP helps you build agents and complex workflows on top of LLMs. LLMs frequently need to integrate with data and tools, and MCP provides:
Okay…
- A growing list of pre-built integrations that your LLM can directly plug into
Hmmm, that reminds me of 2000s and HTML5 when websites started introducing REST APIs that you can “directly plug into” 👀
- The flexibility to switch between LLM providers and vendors
Clouds with their virtualization and s/LLM providers/Linux distributives/
- Best practices for securing your data within your infrastructure
This one is interesting! Let’s dive deeper and go straight to the spec’s Core Components.
“Best practices for securing your data within your infrastructure”
The protocol layer is extremely well thoughtout (I will get back to it in a sec, bear with me).
Quoting the website, once again:
Key classes include:
- Protocol
- Client
- Server
(I will not even start at the “protocol” defined as two code snippets, one in TypeScript and another one in Python)
But clearly we can’t find “Best practices for securing your data within your infrastructure” in the protocol. Let’s keep going and look at the Transport Layer.
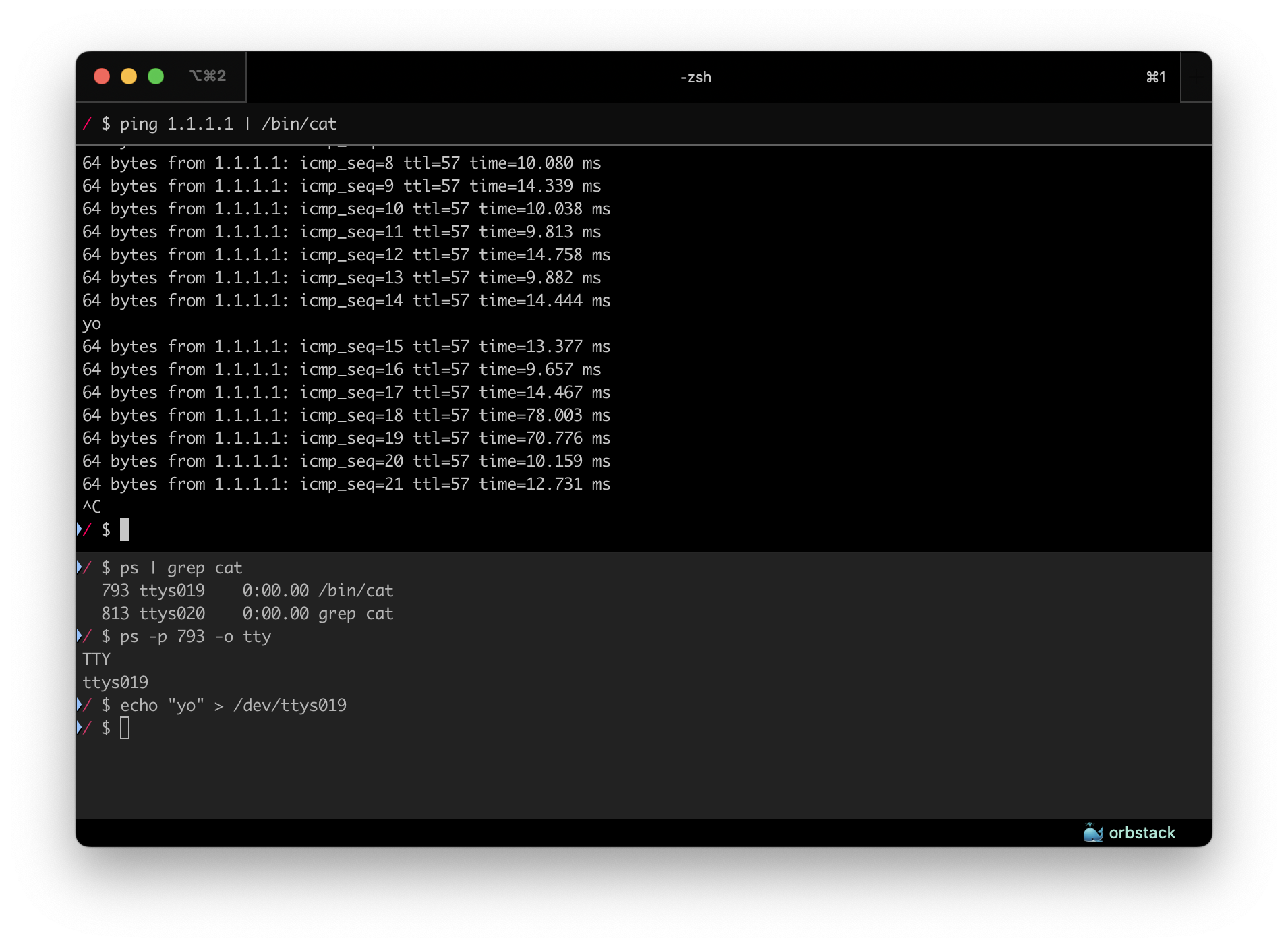
The first and most common transport is… the Stdio transport. Not the best practices I would expect for a protocol that does not implement any security at the protocol level (meaning that it is delegated to the transport level), since STDIO can easily be hijacked:
The second (and… last) option is… HTTP with SSE transport. Okay, finally something older than more than 50% of LLM innovators!
And now comes the best part:
All transports use JSON-RPC 2.0 to exchange messages. See the specification for detailed information about the Model Context Protocol message format.
Please allow SergeiGPT to summarize all of this for you:
MCP is a protocol-not-protocol that allows LLMs to completely ignore the decades of well thoughtout APIs and instead force humans to write API wrappers and expose them via either unantheticated STDIO or HTTP SSE without a single mention of the authentication methods (because that’s what all protocols do, right? right?…) and gives you “Best practices for securing your data within your infrastructure”.
And of course there is a third, WebSocket-based protocol that isn’t even mentioned in the spec.
“Okay, smart-a.. errr… smart-https, can you do better?”
(brb, changing all my Home Assistant pipelines to react to “Okay, smart-ass!”)
You would be wondering, what’s my beef with all of this. No, the protocol wasn’t invented by my ex-colleague that ate my pudding that I forgot to label or anything like that. But I do have a personal beef with this space… kinda.
Spoiler: it is not even the ignorance of existing tech and the duplication of effort that will be obsolete once LLMs will become a tad smarter and be able to call APIs without rm -rf /-ing every now and then.

Original image by Beef (TV series) 2023 ©️ Netflix
In fact, contradictionary to everything I said before, my beef with this is that we were so distracted with Blockchain, Crypto, Web3, NFTs and GenAI that we kidna forgot to move the “core protocols” needle forward.
Let me explain. HTTP was a truly revolutional protocol… for the request/response model.
But the modern world is all about streaming, and not only streaming of media chunks from Netflix when you watch great TV shows like the Beef, but the data streaming in general.
And let’s admit it, modern streaming protocols suck!
I happened to know a thing or two about it because I was part of the Reactive Foundation (sub-foundation of the Linux Foundation) and involved in https://rsocket.io - a modern protocol (started at Netflix, btw!) that would truly be a Streaming-native protocol. Here are some unique things about it:
- Built-in backpressure: not just gRPC’s SHOULD-style “ready / not ready”, but a proper MUST-style backpressure that communicates the demand and fails if the producer does not respect it.
- Transport-agnostic: unlike over-HTTP2, RSocket was able to communicate over a variety of transports, be it TCP, WebSockets, QUIC or nearly anything else that supports bidirectional flow.
- No differentiation between the client & server: you can easily start a request from the server.
The first two are important but, in the context of MCP, let’s focus on the last bulletpoint: directional independence.
Think of it as the Push Notifications on your smartphone that allow you to receive a notification even before you open the app and pull to refresh.
Let’s imagine a world where in 2025 we were not using protocols from 2000s. And no, I am not saying that there isn’t any progress, there is.
HTTP2 Server Push, WebSockets, RSocket, IceRPC (similar to RSocket but tied to QUIC), and even the gRPC despite its major limitations.
All of them allow replacing the inefficient polling (making a request every now and then to check if the status changed using the request/response model) with something better.
But the way they achieve that is what defines the “generation” of such protocol.
Let’s say we want to build a Push Noficications service that allows us to receive a server-issued event that we did not explicitly request.
2000s (HTTP polling)
Here is how we would do it in 2000s (and, tech deflation adjusted, how some legacy Enterprises do it today):
- Define a “/notifications” HTTP endpoint that returns… well… let’s be real, XML, because it is 2000s.
- Start a timer for every N seconds
- Make a request to that endpoint and expect 0..N notifications
GOTO 2
Pros:
- It is damn simple to do!
- Works over plan HTTP
- “Stateless” protocol, no need to maintain a connection
Cons:
- Extremely expensive, basically DDoS-as-a-Service. Every client becomes a member of the botnet that attacks your servers, and you are responsible for creating it!
- Worst case scenario: N seconds delay where N is the timer interval. Imagine reading that “someone opened the window” notification 15 seconds later together with the burglar who is already giving you… err… headpats?
2010s: SSE/gRPC
The cons were so important that we needed a different approach. And the approach is basically to not close the request to “/notifications” and disable buffering, so that we can “listen” to incoming events without re-requesting them over and over.
Pros:
- Still HTTP (even with gRPC, which is HTTP2)
- “Initiate-and-Listen” instead of “request/response”
Cons:
- Must be initiated by the client
- The client must know what to request upfront
- Resumption is… tricky.
- Push-based streaming that does not give the client a chance to do the backpressure and avoid the “fast producer slow consumer” scenario
If you want to experience it yourself, try Wikipedia’s changes stream that is nearly impossible to follow given the amount!
This works fine when you need to subscribe to events, but is it the right protocol to allow the server call a method on the client, which is exactly what MCP does?
2020s: RSocket/IceRPC/WebSockets… and gRPC?
So, how would you do that in 2020s? Let’s finally abandon the client request/server response model and embrace bidirectional communication!
- Define
NotificationsServiceon the initiator (think iPhone) - Initiate (hence the initiator) the connection to the producer and “remember” it in the registry of connections
- When there is a new notification, the producer can call the
NotificationsServicedirectry on the initiator, as if it was the producer that opened a connection to the initiator
Pros:
- No need for any polling, the producer can just call the initiator
- The initiator can respond with backpressure control on every request that the producer is making.
In fact, even “one off” requests can be done in a way that the initiator must confirm that it is ready to accept data before the producer actually sends it after calling the method, Reactive-style - QUIC and other modern stateless/semi-stateless protocols can be used
Cons:
- New paradigm
- The connections need to be tracked on the producer side
- Semi-stateful protocol
For many of you, this would sound a lot similar to gRPC, but can this be done with gRPC? Well… kinda. 🤓
2025(?): bi-directional gRPC
gRPC heavily utilizes HTTP/2 as its transport, which does support Server Push but not used by gRPC.
There is a conversation on the gRPC specification issue tracker about “tunneling” - an ability to establish a bi-directional tunnel over the existing gRPC connection:
https://github.com/grpc/grpc/issues/14101
There was even a functional PoC in grpc-java that implements it:
https://github.com/grpc/grpc-java/pull/3987
In fact, yours truly ended up evolving that PoC into a working solution running in production and serving FAANGs of this world!
Currently implemented for Go and Java (but not limited to, any gRPC impl would do), it allows calling gRPC services on connected clients as if the connection was done directly to them from the server using the client library.
Let’s say, we want to define a client-side health service using Go:
package main
import (
"context"
"log"
"time"
bidi "github.com/bsideup/grpc-bidi/go"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/insecure"
health "google.golang.org/grpc/health/grpc_health_v1"
)
type simpleHealthService struct {
}
func (s *simpleHealthService) Check(context.Context, *health.HealthCheckRequest) (*health.HealthCheckResponse, error) {
panic("unimplemented")
}
func (s *simpleHealthService) Watch(_ *health.HealthCheckRequest, watcher health.Health_WatchServer) error {
for {
select {
case <-watcher.Context().Done():
return watcher.Context().Err()
default:
resp := health.HealthCheckResponse{
Status: health.HealthCheckResponse_SERVING,
}
if err := watcher.Send(&resp); err != nil {
return err
}
<-time.After(time.Second)
}
}
}
func main() {
conn, err := grpc.NewClient(
"localhost:50051",
grpc.WithTransportCredentials(insecure.NewCredentials()),
)
if err != nil {
log.Fatalf("fail to dial: %v", err)
}
defer conn.Close()
server := grpc.NewServer()
health.RegisterHealthServer(server, &simpleHealthService{})
// bidi.NewListener(conn) will create a fully functional listener,
// over the existing gRPC connection
if err := server.Serve(bidi.NewListener(conn)); err != nil {
log.Fatalf("failed to serve: %v", err)
}
}And now we can call it from the server. Let’s say, in Java, to demonstrate it being cross-platform:
package com.example;
import io.grpc.ManagedChannel;
import io.grpc.ManagedChannelBuilder;
import io.grpc.Metadata;
import io.grpc.ServerBuilder;
import io.grpc.bidi.ClientChannelService;
import io.grpc.health.v1.HealthCheckRequest;
import io.grpc.health.v1.HealthCheckResponse;
import io.grpc.health.v1.HealthGrpc;
import io.grpc.stub.StreamObserver;
public class Server {
public static void main(String[] args) throws Exception {
io.grpc.Server server = createServer(50051);
server.start();
System.out.println("Server started on " + server.getListenSockets().get(0));
server.awaitTermination();
}
static io.grpc.Server createServer(int port) {
return ServerBuilder
.forPort(port)
.addService(
new ClientChannelService() {
@Override
public void tune(ManagedChannelBuilder<?> builder) {
builder.keepAliveWithoutCalls(true);
}
@Override
public void onChannel(ManagedChannel channel, Metadata headers) {
// The "channel" here is a "normal" ManagedChannel,
// the same you would get by creating a direct connection to the client.
// each connected client that supports bidi will trigger this method.
// The "headers" metadata can be used to auth & identify sessions, too!
HealthGrpc.HealthStub healthStub = HealthGrpc.newStub(channel);
healthStub.watch(
HealthCheckRequest.getDefaultInstance(),
new StreamObserver<HealthCheckResponse>() {
@Override
public void onNext(HealthCheckResponse healthCheckResponse) {
System.out.println("Health response: " + healthCheckResponse);
}
@Override
public void onError(Throwable e) {
e.printStackTrace();
}
@Override
public void onCompleted() {
System.out.println("Completed");
}
}
);
}
}
)
.build();
}
}As you can see, it is relatively easy in 2025 to break the request/response paradigm and build better APIs!
How does it apply to MCP?
Instead of discussing how it applies to MCP, let’s talk again about what MCP is:
- It is a network protocol
- “Server” is the main actor
- “Client” is a variety of devices, typically behind NAT so we can’t easily establish a server-to-client connection
- Streaming-heavy protocol
None of this really requires a new low/mid level protocol, in fact!
If we weren’t too busy vibe coding games and invested a bit more time in evolving low level protocols, MCP would not exist (at least in the current form) in the first place and instead would be a simple high level protocol, in gRPC or what’s not, something like that:
extend google.protobuf.ServiceOptions {
bool llm_service = 50000;
}
*crickets*That’s it!
“WTH?!” you would say?
Well, guess what, there is already a protocol in gRPC that allows you to introspect defined services!
So we literally don’t need to do anything to allow LLM to discover defined services, because the wheel was already invented long time ago.
So it can (but does not have to) be as easy as hinting which service is an “LLM service”:
service FileSystem {
option (llm_service) = true;
rpc ListFiles(ListFilesRequest) returns (stream ListFilesResponse) {}
rpc ReadFile(ReadFileRequest) returns (stream ReadFileResponse) {}
rpc WriteFile(stream WriteFileRequest) returns (WriteFileResponse) {}
rpc DeleteFile(DeleteFileRequest) returns (DeleteFileResponse) {}
}And btw it will already be infinitely better because it streams files instead of returning large JSONs ;)
What else does it give us? Well, nothing, except the built-in security, load balancers support, SDKs in many popular languages, efficient binary-encoded messages, annotations and reflection for machine-readable introspection, a decade+ of the protocol shaping, and more!
And that’s just by using gRPC, not even the most efficient option for the job 🤷♂️
Conclusion
The hype is unavoidable, but how we navigate the hype typically defines whether we will actually move the needle forward for the industry (like Docker/Kubernetes did with popularizing Go) or we will simply… create NFTs.
Do I think that we need to allow LLMs perform actions on our behalf? Sure, why not.
But CTO in me screams at “JSON RPC over SSE” in the world where we have the power to generate infinite cat images!
Here is one for you, btw:

“C” in “CTO” stands for “Cat”